NO.222 The Future of Development Environments with AI Foundation Models
October 6 - 9, 2025 (Check-in: October 5, 2025 )
Organizers
- Xing Hu
- Zhejiang University, China
- Raula Gaikovina Kula
- Osaka University, Japan
- Christoph Treude
- Singapore Management University, Singapore

Overview
Description of the Meeting
Recently, AI Foundation models (e.g., LLMs like GPT-4, ChatGPT, and Code models like llama2 and Starcoder [5])have attracted attention from both academia and industry. In Software Engineering, several studies showed that these models can achieve remarkable performance in various tasks, e.g., code generation [1], testing [2,3], code review [1], and program repair [1,4]. For example, Hu et al. explored the performance of AI FMs on five software engineering tasks, and they found that AI FMs outperform other state-of-the-art approaches in code generation, unit test case generation, and automated program repair by large margins [1]. Xia et al. found that directly applying AI FM can already substantially outperform all existing APR techniques [3]. Yuan et al. proposed the first ChatGPT-based unit test generation approach which improves the SOTA substantially [4].
Traditionally, the IDE (Integrated Development Environment) has placed source code as the key artifact, and used version control to help manage the project. With the introduction of Foundation Models, the models, data and the natural language used to query the AI FMs will need to be managed. Considering that AI FM such as GPT-4 was developed by AI researchers rather than SE researchers, we are unsure how software engineers interact with Foundational Models. Hence we raise three questions:
-
What should the future IDE look like? How can we improve the experience of human-machine interaction? Do we still need to write the code in the future?
-
What are the challenges and opportunities that Foundational Models bring into light? What are the potential risks and drawbacks associated with using AI FMs in software engineering, and how can they be mitigated?
-
How can we build various AI FM agents into this new IDE?
With respect to designing the IDE, constructing an FM is costly and time-consuming and dependent on the dataset. The high cost of training of FMs requires us to have new engineering techniques to support the training and application of FMs, i.e., LLM engineering. Also, an FM can be trained with different hardware and software platforms, and there are many open-source FMs, e.g., StarCoder [5]. However, it is still unknown how to implement FMs across different hardware and software platforms. In summary, FM engineering has the following challenges:
- What types of data are most suitable for training an FM, and what strategies should be employed for effective AI dataset management?
-
What methods can be utilized to identify and rectify bugs in an FM?
-
What are the strategies for effectively deploying FMs across diverse hardware and software platforms?
-
Given the dependency of prompt design and use on the underlying FM and the varying performance of prompts across different FMs, how should prompts be approached in the context of software engineering? For example, should we consider developing a prompt language that aligns closely with our programming language?
The purpose of this Shonan meeting is to bring together leading researchers and practitioners from three different communities (i.e., Software Engineering, Artificial Intelligence, Human Computer Interaction). We need to understand how these diverse fields can contribute to the advancement of software engineering in the era of AI, and what roles each discipline can play in addressing the emerging challenges and opportunities posed by FMs.
The aim is not only to foster an exchange of ideas, but also to outline a clear set of concrete grand challenges and propose a roadmap for how those challenges can be met by future work. To accomplish our goal, we will follow the schedule:
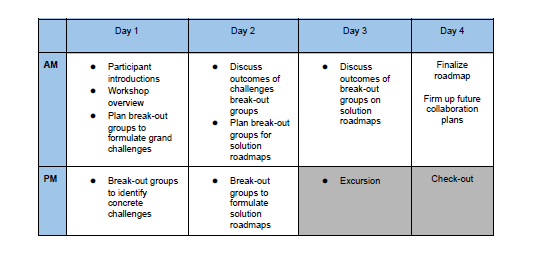
A tangible outcome of the Shonan meeting will be a manuscript that describes the grand challenges and our roadmap for future IDEs. The produced manuscript will be submitted as a vision paper to a conference or journal.
Reference
[1] Xing Hu, Hailong Wang, Zhenhao Li, Xin Xia, David Lo. Is State-of-the-Art LLM A Silver Bullet to Automated Software Engineering? Under Review.
[2] Yinlin Deng and Chunqiu Steven Xia and Chenyuan Yang and Shizhuo Dylan Zhang and Shujing Yang and Lingming Zhang. Large Language Models are Edge-Case Fuzzers: Testing Deep Learning Libraries via FuzzGPT. https://arxiv.org/abs/2304.02014
[3] Xia, Chunqiu Steven, Yuxiang Wei, and Lingming Zhang. "Practical Program Repair in the Era of Large Pre-trained Language Models." arXiv preprint arXiv:2210.14179 (2022).
[4] Yuan, Zhiqiang, et al. "No More Manual Tests? Evaluating and Improving ChatGPT for Unit Test Generation." arXiv preprint arXiv:2305.04207 (2023).
[5] Li, Raymond, et al. "StarCoder: may the source be with you!." arXiv preprint arXiv:2305.06161 (2023).