NO.213 Augmented Multimodal Interaction for Synchronous Presentation, Collaboration, and Education with Remote Audiences
June 24 - 27, 2024 (Check-in: June 23, 2024 )
Organizers
- Matthew Brehmer
- Tableau Research, United States
- Maxime Cordeil
- The University Of Queensland, Australia
- Christophe Hurter
- ENAC- Ecole Nationale de l’Aviation Civile, France
- Takayuki Itoh
- Ochanomizu University, Japan

Overview
Introduction
Throughout the last two decades, we have seen an increasing demand for remote synchronous communication and collaboration solutions across professional and educational settings. However, it was the COVID-19 pandemic and the urgent shift to remote and hybrid work and education that fundamentally altered how people communicate, collaborate, and teach at a distance. Across government and enterprise organizations, people need to achieve consensus and make decisions grounded in data, and these activities now often take place via teleconference applications and collaborative productivity tools. Meanwhile, educators at all levels have had to similarly adapt to teaching remotely, and this adaptation has presented challenges and opportunities to innovate with respect to teaching STEM (science, technology, engineering, mathematics) subjects and those that depend on numeracy, abstract representations of data, and spatial reasoning. Popular teleconference tools such as Zoom, Cisco Webex Meetings, Slack Huddles, Google Meet, and others typically afford multimodal communication including multi-party video and audio conferencing, screen sharing, breakout rooms, polls, reactions, and side-channel text chat functionality. Often these tools are used in conjunction with collaborative productivity tools, and collaboration platforms organized by channels and threads, such as Slack or Microsoft Teams, forming synchronous episodes within a larger timeline of asynchronous communication.
Despite the multimodal nature of these meetings and presentations, the presenter and audience experiences are often poor substitute for co-located communication, particularly when a speaker presents complex or dynamic multimedia content such as data visualization via screen-sharing (see Brehmer & Kosara, VIS 2021 <https://arxiv.org/abs/2107.09042). When screen-sharing, the presenter is often relegated to a secondary thumbnail video frame, and only they can interact with the shared content using mouse and keyboard controls. In contrast, consider co-located communication scenarios such as those in meeting rooms or lecture halls, where all participants can use their physical presence and body language to interact with and point to the multimedia content being discussed. In particular, embodied cognition research suggests that nonverbal hand gestures are essential for comprehending complex or abstract content, such in mathematics education, in engineering and design, and in business decision-making.
Some telecommunication tools have recently introduced ways to restore the missing embodied presence of a presenter as they share multimedia content such as slides, data visualization, diagrams, and interactive interfaces. For instance, Cisco Webex Meetings and Microsoft Teams offer functionality to segment the presenter’s outline from their webcam video and composite them in front of screen-shared content. Virtual camera applications have also become popular, including mmhmm and OBS Studio; these tools allow for considerable flexibility with respect to video compositing, and are compatible with most teleconferencing applications. However, only a single presenter can interact with shared content, and they must do so using standard mouse and keyboard interfaces.
Meanwhile, advancements in extended reality (XR) and immersive analytics suggest multimodal approaches that bypass standard desktop environments. VR meeting spaces are an emerging trend in enterprise settings, in which all participants join a meeting as an avatar in an immersive 3D conference room. While the potential of XR for remote multimodal communication around data is promising, it also exhibits several limitations. The first issue is the lack of general access to affordable and comfortable hardware devices, including depth sensors and head-mounted displays; moreover, many XR applications require multi-device coordination with hand-held pointing devices or simultaneous touch-screen interaction. A second issue is a relatively higher amount of fatigue induced by XR applications incorporating head-mounted displays. A third issue is the difficulty of maintaining side-channel chat conversations in an XR environment. Lastly, sharing and interacting with complex and dynamic multimedia content in XR remains to be tedious and error-prone.
Recently, an exciting alternative approach to remotely presenting rich multimedia content with remote audiences has emerged: the combination of publicly-available computer vision and speech recognition models with commodity webcam and microphones has the potential to bring the immersive experience of XR to remote communication experiences without abandoning a familiar desktop environment. This combination allows for real-time video compositing and background segmentation, pose and gesture recognition, and voice commands, thereby giving people multiple modalities with which to interact with representations of data. We have already seen applications in this space for presenting business intelligence content in enterprise scenarios (see Hall et al, UIST 2022 <https://arxiv.org/abs/2208.04451), for presenting STEM topics in online education and personalized product marketing (see Liao et al, UIST 2022 https://arxiv.org/abs/2208.06350), and for interacting with large cultural collections (see Rodighiero et al, Information Design Journal 2023 <https://dx.doi.org/10.1075/idj.22013.rod), such as those in gallery and museum archives.
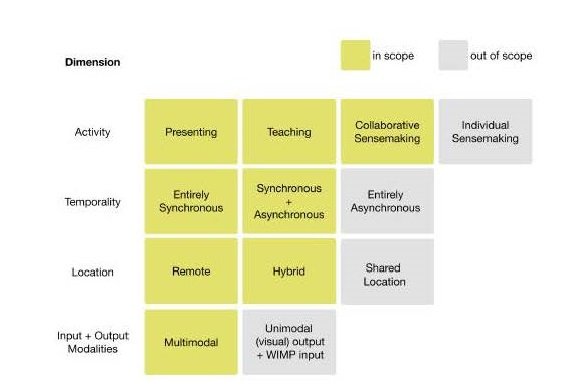
Our seminar is a continuation and extension of the themes discussed atthe MERCADO workshop at IEEE VIS 2023 <https://sites.google.com/view/mercadoworkshop/home> in Melbourne, Australia. It lies at the crossroads of data visualization, human computer-interaction, computer-supported collaborative work, and online education, and is an opportunity to gather those who are similarly captivated by the potential of new interactive experiences for synchronous and multimodal communication and collaboration around data with remote or hybrid audiences. The scope of our proposed seminar can also be summarized by the following diagram:
Aim of the seminar
Our seminar will focus on emerging technologies and research that can be applied to multimodal interaction for remote communication and collaboration around data. It will also serve as a forum to identify new application scenarios and expand upon existing ones, and as a forum to test new interaction techniques applicable across these scenarios. We anticipate that the results of this seminar may include contributions to several academic communities including those affiliated with the IEEE VGTC (VIS, PacificVis, ISMAR, Eurovis) and ACM SIGCHI (CHI, CSCW, UIST, ISS).
We will invite participants to submit ideas and reflection relating to the following topics research questions:
MULTIMODAL REMOTE COLLABORATION AROUND DATA
Considering recent work exploring the design space of synchronous remote collaboration around data via a shared WIMP interface, how can these techniques be extended to incorporate additional modalities?
ADAPTING CO-LOCATED COLLABORATION APPROACHES TO REMOTE / HYBRID SETTINGS
Considering techniques for co-located collaborative work around data, whether using conventional desktop workstations or immersive augmented reality head-mounted displays, how can these techniques be expanded to support hybrid or remote collaboration and communication?
COMMUNICATION AROUND DATA TO LARGE BROADCAST AUDIENCES
Considering presentation techniques employed by television news broadcasters for presenting technical or data-rich stories (e.g., weather, finance, sports), how can these techniques be applied (while keeping production costs low) and expanded to support multi-party multimodal interaction around data at a distance?
LIVESTREAMING ABOUT DATA
Considering presentation and video compositing techniques employed by livestreamers (e.g., Twitch, YouTube, Facebook Live) and recorded video content creators (e.g., YouTube, Tik-Tok), how can these techniques be applied during synchronous communication and collaboration around data, as well as in conjunction with multimodal interaction (e.g., pose / gesture input, voice prompts, proxemic interaction)?
ADAPTING COLLABORATIVE XR EXPERIENCES
Considering the techniques by which individuals display and interact with representations of data in XR (AR / VR), how can we extend or adapt these techniques? In other words, how can techniques initially designed with expensive or exclusive hardware be adapted to low-cost, accessible commodity input and output devices? Similarly, how could augmented video techniques designed for use with depth sensors and pointing devices be similarly adapted?
SUPPORTING DIFFERENT COMMUNICATION ROLES
Currently, most teleconference applications assume a single speaker / presenter, with other participants in audience roles. How can we support multi-party augmented video interaction? Alternatively, how can we support both ‘sage on the stage’ and ‘guide on the side’ style communication, differentiating an orator from a discussion facilitator. Similarly, how can we support formal, linear, and scripted presentations as well as informal, unscripted, interruption-prone, and collaborative discussions?
DEFINING A DESIGN SPACE
Overall, what are the dimensions of the design space for multimodal and synchronous communication and collaboration around data? Where does existing work fit within this design space and which parts remain underexplored?
Ultimately, our aim is to identify a timely and urgent research agenda that the community gathered during this seminar can pursue. We aim to report the emerging research directions that we will identify in a top quality outlet research venue such as IEEE TVCG or ACM CHI.
Aim of the seminar
During this seminar, we will foster discussions with researchers and practitioners around emerging technology to support synchronous multimodal communication with remote audiences. The proposed seminar is related to the following list of previous Shonan and Dagstuhl meetings:
- Immersive Analytics: A new multidisciplinary initiative to explore future interaction technologies for data analytics (Shonan, 2016) (/seminars/074/)
- Immersive Analytics (Dagstuhl, 2016) (https://www.dagstuhl.de/en/program/calendar/semhp/?semnr=16231)
- Data-Driven Storytelling (Dagstuhl, 2016) (https://www.dagstuhl.de/en/program/calendar/semhp/?semnr=16061)
The proposed seminar is also related to previous ACM CHI and IEEE VIS workshops:
- Visualization for Communication (VisComm, IEEE VIS 2018 – 2022) (https://ieeevis.org/year/2022/info/workshops#viscomm)
- Immersive Analytics (IEEE VIS 2017, ACM CHI 2019, 2020, 2022) (https://ia2workshop2022.github.io/)
- Death of the Desktop – Envisioning Visualization without Desktop Computing (IEEE VIS 2014)
- Emerging Telepresence Technologies in Hybrid Learning Environments (CHI 2022 workshop) (https://chi2022emergingtelepresence.godaddysites.com/)
- Social VR (CHI 2021, CHI 2020) (https://www.socialvr-ws.com/)
The proposed meeting will focus on emerging technologies and research that can be applied to augmented video interaction for remote communication. It will also serve as a forum to identify new application scenarios and expand upon existing ones, and as a forum to prototype and test new interaction techniques applicable across these scenarios. We anticipate that the results of this meeting may include contributions to several academic communities including those affiliated with ACM SIGCHI (CHI, CSCW, UIST) and the IEEE VGTC (VIS, PacificVis, ISMAR, Eurovis). During this seminar, participants will reflect upon the following research questions:
1. Considering presentation techniques employed by television news broadcasters for presenting technical or data-rich stories (e.g., weather, finance, sports), how can these techniques be applied and expanded upon in augmented video interaction? [see Drucker et al, Zhao and Elmqvist]
2. Considering video compositing techniques employed by livestreamers (i.e., Twitch, YouTube, Facebook Live) and recorded video content creators (e.g., YouTube, TikTok), how can these techniques be applied during synchronous communication and in conjunction with multimodal interaction (e.g., pose, gesture, voice, etc.)
3. Considering the techniques by which people represent and interact with multimedia content in immersive XR (VR / AR) how can we extend or adapt these techniques to augmented video interaction? In other words, how can techniques initially designed with expensive / exclusive hardware be adapted to low-cost, accessible hardware contexts?
a. Similarly, how could augmented video techniques designed for use with depth sensors [see Saquib et al] and pointing devices [see Perlin et al] be adapted to low-cost, accessible hardware contexts?
4. Currently, augmented video interaction assumes a single speaker / presenter, with other participants in audience roles. How can we support multi-party augmented video interaction? [see Grønbæk et al]
b. Supporting “Sage on the Stage” vs “Guide on the Side” style communication (or, orator facilitator, or similarly, the distinction between formal, linear, and scripted concert recitals and informal, unscripted, and collaborative jam sessions).
5. Overall, what are the dimensions of the design space for augmented video interaction? Where does existing work fit within this design space and which parts remain underexplored?
Ultimately, our aim is to identify timely and urgent research actionable items that the community gathered during this Shonan meeting can pursue. We aim to report the emerging research directions that we will identify in a top quality outlet research venue such as ACM CHI or IEEE TVCG. In addition, the format of the Shonan meeting will allow us to generate a series of low and high fidelity prototypes that we will share with the broader community on the web. Finally, we anticipate gathering a collection of existing examples of augmented video interaction and compiling these into a browsable online gallery.
Attendees
30 people with at least 10 Japanese researchers.
Aldugom, Mary, Kimberly Fenn, and Susan Wagner Cook. "Gesture during math instruction specifically benefits learners with high visuospatial working memory capacity." Cognitive research: principles and implications 5.1 (2020): 1-12.
Bjuland, Raymond, Maria Luiza Cestari, and Hans Erik Borgersen. "The interplay between gesture and discourse as mediating devices in collaborative mathematical reasoning: A multimodal approach." Mathematical Thinking and Learning 10.3 (2008): 271-292.
Brehmer, Matthew. "The Information in Our Hands." Information+ conference presentation (2021): https://vimeo.com/592591860
Brehmer, Matthew, and Robert Kosara. "From Jam Session to Recital: Synchronous Communication and Collaboration Around Data in Organizations." IEEE Transactions on Visualization and Computer Graphics 28.1 (2021): 1139-1149.
Cash, Philip, and Anja Maier. "Prototyping with your hands: the many roles of gesture in the communication of design concepts." Journal of Engineering Design 27.1-3 (2016): 118-145.
Clarke, Jean S., Joep P. Cornelissen, and Mark P. Healey. "Actions speak louder than words: How figurative language and gesturing in entrepreneurial pitches influences investment judgments." Academy of Management Journal 62.2 (2019): 335-360.
Cornelissen, Joep P., Jean S. Clarke, and Alan Cienki. "Sensegiving in entrepreneurial contexts: The use of metaphors in speech and gesture to gain and sustain support for novel business ventures." International small business journal 30.3 (2012): 213-241.
Derry, Lins, et al. "Surprise Machines: Revealing Harvard Art Museums’ Image Collection." To appear in Information Design Journal (2022) / Information+ 2021: https://vimeo.com/595473865
Drucker, Steven, et al. "Communicating data to an audience." Data-driven storytelling. AK Peters/CRC Press, 2018. 211-231.
Edwards, Laurie D. "Gesture and mathematical talk: Remembering and problem solving." Proceedings of the American Educational Research Association Conference (2005).
Grønbæk, Jens Emil, et al. "MirrorBlender: Supporting Hybrid Meetings with a Malleable
Video-Conferencing System." Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 2021.
Hall, Brian D., Lyn Bartram, and Matthew Brehmer. "Augmented Chironomia for Presenting Data to Remote Audiences." Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology. 2022.